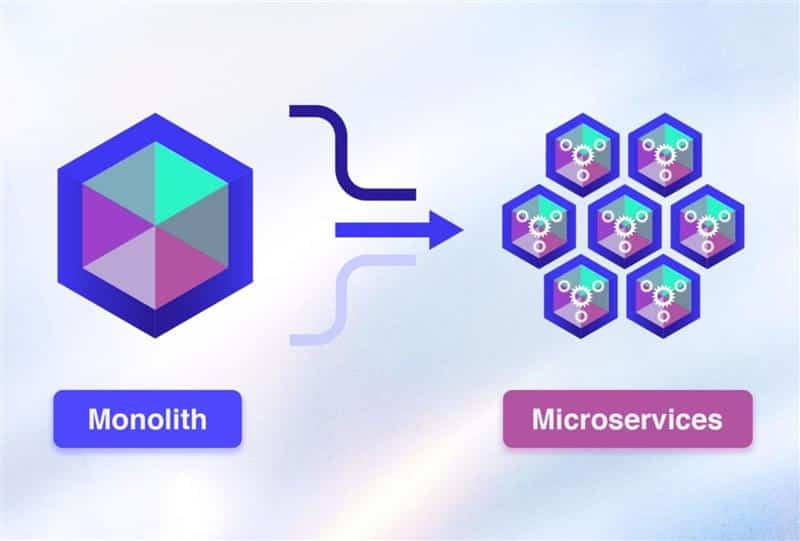
Many organizations still rely on large monolithic applications. Over time, those systems become harder to scale, update, and maintain. A shift from monolith to microservices often appears as a solution. Yet the transition is rarely simple. Microservices introduce flexibility, but they also add operational complexity, infrastructure demands, and new architectural decisions.
A thoughtful migration strategy helps reduce those risks. Many teams use the strangler pattern to move features gradually from a monolith to microservices. Step-by-step refactoring allows services to grow without interrupting existing operations.
This guide explains practical methods for a safe transition. You will explore architectural refactoring patterns, database decomposition, and incremental migration approaches that keep business systems stable during the transformation.
What Is Monolith Architecture
Monolith architecture refers to a software architecture where the entire application works as one unit. A monolithic application combines the user interface, business logic, and data access layer in a single codebase. Most systems operate as a single process monolith connected to a single database. Early products often start with monolithic architecture because development is simple and fast. One technology stack manages the business domain inside the monolithic system.
Many legacy systems and existing monolithic systems still follow this model. The entire system usually depends on a shared database with foreign key relationship rules that protect transactional integrity. That structure helps maintain data consistency and supports easier end-to-end testing. Teams also manage business capabilities through a central domain model.
Problems appear when the existing architecture grows larger. Scaling the entire monolith across multiple machines becomes complex. Updates affect the entire system, which introduces new failure modes. For that reason, many organizations consider monolith to microservices migration toward a microservices architecture that separates services and modernizes system architecture.
What Is Microservices Architecture
Microservices architecture is a modern software architecture where an application runs as many small services instead of one large monolithic system. Each service focuses on a specific business domain and owns its own data. Teams design clear service boundaries so services can evolve independently. Unlike a monolithic architecture with a shared database, microservices often use separate data stores. Services communicate through well-defined APIs in an API-first architecture, messaging, or message interception across multiple machines.
This system architecture supports application and database decomposition. Each service handles a specific functionality pattern or business capability. Domain-driven design helps teams define the domain model and separate responsibilities across services. Independent services allow teams to use different programming language choices and technology stack decisions.
Microservices architecture improves scalability and flexibility. Teams deploy more services without affecting the entire system. However, distributed systems introduce new failure modes, data consistency challenges, and distributed transactions that require synchronization strategies and careful system design.
Why Migrate From Monolith To Microservices
Most applications begin as monoliths designed for specific business use cases. Organizations migrate to microservices architecture for concrete business advantages that affect their bottom line and competitive position directly. This shift is often part of a broader scalable software architecture strategy for high-growth products. According to Gartner, 74% of surveyed organizations currently use microservices architecture, with another 23% planning to do so.
Scalability Benefits
Scaling a monolithic system means scaling everything at once. You just need more capacity for one component, you scale the entire monolith. This approach wastes resources and drives up infrastructure costs.
Microservices architecture changes this equation completely. You can scale individual services based on specific patterns of what you just need. Spotify experiences high volume at the time of a major album release. They scale up audio delivery and playlist services independently without affecting user authentication or payment processing. Airbnb scales search and booking services during peak seasons while keeping host messaging and review systems at normal capacity.
Faster Time To Market
Monolithic architectures create bottlenecks that slow down development. Multiple teams must coordinate for one large release. This coordination burden increases the time it takes to add new features. You might find that adding new features becomes difficult when your business or user base grows.
Microservices architecture accelerates software development by enabling continuous delivery and deployment processes. Multiple teams can build, test, and launch individual services simultaneously. Development and testing proceed faster when teams work without interference.
This parallel development model speeds up time to market substantially. One team works on a new payment gateway while another focuses on user authentication. Both teams operate independently, make changes, and deploy without waiting for a monolithic application to be recompiled and tested end to end.
Improved Robustness And Failure Isolation
A bug or error in one part of a monolithic application might render the entire system unusable. One component fails and brings down everything because all processes are tightly coupled.
Microservices architecture provides fault isolation that protects your entire system. One service fails and doesn’t affect the others. They keep working. A recommendation engine crashes, users can still browse products, add items to their cart, and check out.
This isolation improves system dependability and uptime substantially. Problems in one area stay contained and don’t affect the functionality of others. Circuit breakers and similar patterns allow services to handle failures smoothly when dependencies are unresponsive.
Team Autonomy And Organizational Benefits
Microservices enforce an organizational structure of autonomous, long-standing teams. Each team takes responsibility for one or multiple services. Small, focused teams concentrate on a particular service’s development, deployment, and maintenance without being burdened by the complexities of the entire system.
This autonomy encourages a sense of ownership and expertise within teams. Team members make informed decisions, iterate quickly, and maintain high quality within their domain. Each team chooses the best technologies for their service and moves at their own pace without waiting for organization-wide coordination or redeployment cycles.
When To Consider Monolith To Microservices Migration
Migration decisions shouldn’t stem from FOMO or reading tech blogs. The first question you need to ask isn’t how to migrate from monolith to microservices, but whether you should. Organizations start this journey with aspirations like increasing scale, accelerating pace of change, and escaping high cost of modifications. These goals matter, but you need concrete criteria.
Clear Goals And Expected Outcomes
Conduct a full picture of your current monolithic architecture before touching a single line of code. Analyze your application’s performance, dependencies, components, and structure. This preparatory work identifies pain points and creates a strategic plan for the transition.
Define clear business objectives for your microservices-based system. Outline how the new architecture will support potential growth and address flaws in your existing monolithic system. Are you struggling with long deployment cycles? Do different components need different scaling characteristics? Does the monolithic codebase limit team autonomy? These questions help justify the migration effort.
When To Avoid Migration
Microservices solve scaling problems you might never have. Stick with the monolith if your team is smaller than 10 people. Stick with the monolith if you deploy once a month. Stick with the monolith if you don’t have dedicated DevOps expertise. Microservices make sense when your team is larger than 15-20 people, you deploy multiple times per week, different parts of your system have different scaling needs, and you have real operational expertise.
Some businesses do just fine with a monolith, especially when their app is simple, stable, and not changing much. A small employee portal or inventory system that only a handful of people use doesn’t need microservices. In these situations, teams often weigh refactor vs rebuild strategies for software modernization instead of committing to a full architectural overhaul. Breaking it into microservices just adds complexity for no real gain if it’s working fine and doesn’t need constant updates.
Signs Your Monolith Is Ready For Migration
A monolith may start to become cumbersome as new features are added to it. Many developers working on a singular codebase face more frequent code conflicts. The risk of updates to one feature introducing bugs in an unrelated feature increases. Think about migration when these patterns arise.
Applications with independent business domains, varying scaling needs, or requirements for independent deployment are good candidates. Your monolithic application faces challenges as software development effort increases with code complexity [previous context]. These are also clear signals that broader software modernization for modern businesses may be necessary. Developers spend more time managing code files instead of building new features.
Monolith To Microservices Migration Strategies
Multiple migration patterns exist for moving from monolith to microservices architecture. The right strategy depends on your monolithic system structure and business constraints.
Monolith To Microservices Strangler Pattern
The monolith to microservices strangler pattern offers a solid framework for incremental migration. The name comes from strangler fig vines that grow around a host tree and replace it over time.
You create a facade in front of the legacy system and reroute functionality through that facade to new services. The old and new systems coexist until migration completes. A routing layer sits in front of your monolith and forwards requests to new microservices. You update routing rules as you extract functionality.
Branch By Abstraction Pattern
Branch by abstraction works when you need to modernize components that exist deeper in the legacy application stack and have upstream dependencies. The strangler pattern intercepts calls at the perimeter, but branch by abstraction handles internal components.
Create an abstraction layer representing interactions between the code to be modernized and its clients. Change existing clients to use this new abstraction. Build a new implementation of the abstraction with reworked functionality outside the monolith. Switch the abstraction to the new implementation when ready.
Use feature toggles to switch between old and new implementations. This pattern allows multiple implementations to coexist in the software system. You maintain continuous delivery because your code works at all times throughout restructuring.
Extract Services From The Monolith
Extracting modules from the monolith and converting them into services is the only way of eliminating the monolith. Identify sticky capabilities that change most often. Developers can extract microservices from these capabilities one service at a time, especially when evolving into scalable SaaS tools that power global business growth.
Apply domain driven design techniques to find bounded contexts defining service boundaries. Run event storming workshops to identify business subdomains. Refactor code within the monolith into well-defined chunks with strict separation of concerns.
Implement New Functionality As Services
New functionality implemented as services is a good way to begin migration. This approach is sometimes easier than breaking apart the monolith. It demonstrates to the business that using microservices substantially accelerates software delivery.
Refactor Monolith To Microservices Database Patterns
Data separation is the hardest phase of any microservices migration. Shared databases create hidden coupling in monolithic architecture and often act as the main force binding a monolith together. Foreign key constraints, cross-schema joins, database triggers and shared stored procedures encode hidden dependencies that undermine service isolation, and they can also limit broader SaaS scalability strategies for sustainable growth.
Database View Pattern
The database view pattern exposes your data source as a single, read-only view for all consumers. This pattern suits read-only applications where services need access to monolithic data without modification rights. You create a view layer that multiple services can query without touching the underlying schema. It’s a straightforward approach when you need temporary read access during migration.
Database Wrapping Service
Database wrapping service hides the database behind a service that acts as a thin wrapper. This moves database dependencies to become service dependencies. This pattern works well when the underlying schema is too hard to think over pulling apart. You place an explicit wrapper around the schema and make it clear that data can be accessed only through that schema. This prevents the database from growing any further. It outlines what is yours versus what is someone else’s.
Split The Database First Approach
Splitting the database first means you migrate data into service-specific databases before extracting code. You move tables to new databases, handle data synchronization and then shift application logic over time. This approach forces you to address data ownership and consistency issues upfront. You’ll deal with eventual consistency since you lose cross-system ACID transactions.
Split The Code First Approach
Split the code first keeps the monolithic database in place and then migrates data to separate databases over time. For an original extraction, it’s acceptable for a newly extracted service to connect to the monolith’s database, provided it interacts with the tables for which it is the logical owner. The new service should be the sole writer to its tables. Other parts of the system must access that data through the service’s API rather than through database reads or writes.
Handle Transactions With Sagas
Traditional ACID transactions do not work well in a distributed system. The Saga pattern uses a series of local transactions and compensating actions to ensure eventual consistency. Each local transaction updates the database and publishes a message or event to trigger the next local transaction. If a local transaction fails, the saga executes compensating transactions that undo the changes made by preceding local transactions.
Challenges And Solutions Of Migrating Monolith To Microservices
Many companies plan a shift from monolith to microservices to improve scalability and flexibility. Yet the migration process introduces technical and operational challenges. Teams must rethink system architecture, data flow, and service design. Clear strategies and tested patterns help organizations manage risk and maintain business as usual during the transition.
Service Boundaries And Business Domain Clarity
A successful monolith to microservices transition begins with clear service boundaries. A monolithic application usually groups many business capabilities inside one codebase. Microservices architecture requires each service to represent a specific business domain.
Domain driven design helps teams define a clean domain model. The process separates functionality pattern areas and identifies services that own data. Many migration guides show illustrative examples where companies map business capabilities before splitting the existing monolithic system.
Research from the CNCF ecosystem report shows that over 70 percent of organizations adopt microservices to improve scalability and faster deployment. A well-defined domain model reduces confusion and prevents bad service decomposition.
Database Decomposition And Data Ownership
Database decomposition becomes one of the hardest parts of migrating monolith to microservices. A monolithic system usually relies on a shared database with strong foreign key relationship rules. That structure ensures transactional integrity and data consistency.
Microservices architecture requires each service to own data. Teams must break the shared database into separate stores aligned with service boundaries. Techniques like split table, database view pattern, and database wrapping service pattern help maintain referential and transactional integrity during the transition.
Companies also use synchronization strategies and change data capture to keep data consistent across services. Gartner reports that poor database decomposition causes nearly 60 percent of failed microservices projects.
Data Consistency And Distributed Transactions
A monolithic architecture maintains strong transactional integrity because all operations run inside one database. Microservices introduce distributed transactions across services and multiple machines. That shift creates new failure modes.
Teams must design systems that synchronize data across services without a shared database. Approaches such as event driven communication and message interception help services exchange information safely. Synchronization strategies protect data consistency even when services fail, similar to how careful planning underpins smooth cloud migration for growing teams.
Architectural refactoring patterns delves into several architectural refactoring patterns that address this issue. Proven method examples include change data capture pipelines and fallback mechanism strategies.
Incremental Migration Without System Disruption
A complete rebuild of the entire monolith is usually a bad idea. Incremental migration offers a safer path. Teams gradually move features from the monolithic application to microservices, often guided by specialized tech consulting services that help modern businesses grow.
The strangler approach is one of the most insightful migration patterns. A mapping engine routes requests between the existing system and new services. Widget composition and API gateways also help redirect traffic.
This proven method allows maintaining business as usual while services evolve. Industry surveys show that more than 80 percent of successful migration projects use incremental migration rather than full replacement.
Communication Between Services
Microservices architecture introduces complex service communication patterns. A monolithic system usually handles calls inside one process. Microservices operate across multiple machines and networks.
System architecture must define how services begin addresses communication. REST APIs, message queues, and event streams are common choices. These decisions are as strategic as choosing between custom vs off-the-shelf software for the broader platform. Message interception also helps capture events between services.
Testing communication becomes critical. End to end testing ensures that services exchange data correctly. Teams often simulate multiple scenarios and failure modes to validate system behavior.
Operational Complexity And Failure Management
Microservices provide flexibility but increase operational complexity. A monolithic application has fewer deployment units. Microservices introduce many services that run across distributed infrastructure.
Each service adds new failure modes. Monitoring tools must track performance across the entire system. Observability platforms analyze logs, metrics, and traces across services.
Netflix reported that its microservices ecosystem runs thousands of services across multiple machines. Robust fallback mechanism design and resilience patterns help systems recover from service failures.
Architecture Refactoring And Long Term Strategy
Architectural refactoring patterns guide organizations through a structured migration process. Several architectural refactoring patterns focus on application and database decomposition. Database wrapping service, database view, and migrating functionality pattern approaches help modernize legacy systems.
Many database migration examples show how companies move data without breaking referential relationships. Tested patterns also protect local developer experience and reduce risk.
A clear strategy helps companies determine reversible and irreversible decisions. Rebuild helps companies determine whether a full replacement or gradual transition offers the same benefits. Practical advice and many illustrative examples support successful migration from monolithic architecture to microservices architecture.
GainHQ’s Approach To Monolith To Microservices Migration Strategy
GainHQ supports product teams that manage both monolithic architecture and microservices architecture. The platform gives teams a unified view of work across services and systems. Product leaders can track dependencies across the entire system and maintain clarity during monolith to microservices migration. Clear visibility helps teams understand how each service connects to the existing system architecture and business domain, supported by ongoing insights from the GainHQ blog on software development and digital transformation.
GainHQ also helps teams maintain coordination when systems grow into multiple services. Centralized planning improves ownership across service boundaries and business capabilities. Teams align product work with architectural milestones so incremental migration happens without disrupting delivery, much like coordinating scalable SaaS tools that power global business growth. Structured workflows help organizations evolve from an existing monolithic system toward scalable microservices architecture while maintaining business as usual, and the same disciplined approach can enable milestones such as launching an MVP in 90 days.
GainHQ also strengthens operational awareness. Teams gain better visibility into system behavior, dependencies, and service outcomes across distributed systems. That insight helps engineering teams manage complexity, reduce risk during architectural changes, and support successful migration strategies across modern SaaS platforms, while leaving space to invest in product improvements such as AI features that increase engagement or custom software that transforms core operations. As systems evolve, pairing strong architecture with thoughtful UX to reduce SaaS churn and improve retention and dedicated UI/UX design services for SaaS products ensures that the technical migration also delivers clear value to end users.
FAQs
Can A Small Engineering Team Successfully Move From Monolith To Microservices?
Yes. A small team can migrate from monolithic architecture to microservices architecture with a gradual plan. Incremental migration and tested patterns help teams refactor a monolithic system without breaking the entire system. Clear service boundaries and domain driven design simplify the transition.
Is A Shared Database Recommended During Monolith To Microservices Migration?
No. A shared database creates tight coupling between services. Microservices architecture usually requires each service to own data to maintain service boundaries. Patterns such as database wrapping service, database view pattern, and database decomposition help teams transition from a shared database while protecting data consistency.
Can Monolith To Microservices Migration Improve System Scalability?
Yes. Microservices architecture allows teams to scale individual business capabilities instead of the entire monolithic application. Services run across multiple machines and handle workloads independently. That system architecture improves performance, resource efficiency, and reliability compared to a single process monolith.
Do Distributed Systems Always Require Distributed Transactions?
No. Distributed transactions are often avoided in microservices architecture. Teams usually rely on synchronization strategies like change data capture, message interception, or event driven communication. These approaches maintain transactional integrity and data consistency across services.
Which Proven Method Helps Extract Services From A Monolithic Application?
The strangler pattern is a proven method for service extraction. A routing layer forwards requests between the existing system and new services. Over time, functionality pattern modules move from the monolithic application to microservices architecture without disrupting business operations.
Growing products require stronger engineering teams. Many companies reach a point where the existing team cannot handle new features, user demand, or faster release cycles. Scaling engineering team becomes essential for maintaining product quality and development speed.
Scaling a team involves more than hiring more developers. Leaders must improve hiring strategies, team structure, and engineering processes. Clear communication, efficient workflows, and the right tools help teams grow without creating bottlenecks.
A thoughtful approach allows companies to expand engineering capacity while maintaining productivity, collaboration, and consistent code quality across the organization.
What Does Scaling Engineering Team Mean
Scaling engineering team refers to the process of expanding an engineering team while maintaining strong code quality, collaboration, and delivery speed, which depends heavily on having a scalable software architecture for high-growth products. Most companies start with small teams where engineers work as a single team. As the team grows, engineering leaders hire new engineers and senior engineers to support rapid growth and new software projects. Successful scaling engineering allows the existing team to continue building software without increasing technical debt.
A strong engineering organization focuses on structured hiring, a clear interview process, and a consistent hiring bar for engineering talent. The hiring manager and leaders define roles for new hires and introduce practices such as code review, design docs, and architecture reviews. Clear company culture, strong engineering culture, and regular performance reviews help remote engineering teams and other teams collaborate effectively as the organization matures.
Signs That Show Engineering Team Is Ready For Scaling
Your existing team sends clear signals when it reaches capacity limits. Engineering leaders who recognize these warning signs can time scaling decisions better than those who react to crises after velocity collapses.
Rapid Product Demand Increase
A customer base that grows faster just needs additional resources to support their needs. Post-product-market fit, demand often outpaces what small teams can deliver without compromising code quality or burning out senior engineers. This represents a positive signal that your product strikes a chord with the market, but it also creates pressure on your engineering organization to maintain service levels.
Customer growth relates to engineering workload. Support requests multiply. Infrastructure demands increase. Feature requests accumulate faster than your existing team can address them. Companies that achieve product-market fit face a critical decision point. Scaling the engineering talent pipeline allows organizations to capitalize on market momentum by iterating faster and capturing larger market share.
Growing Engineering Workload And Backlog
Missing deadlines shows that your existing team is stretched thin and just needs reinforcements to meet project timelines. Engineers spend only 32% of their time writing or improving code. The remainder gets consumed by meetings, context switching, and firefighting. This imbalance signals capacity constraints that hiring alone won’t fix without addressing the reasons it happens.
Burnout rates provide another warning indicator. 65% of engineers report experiencing burnout within the past year. Overworked engineers make more mistakes and produce lower code quality. They leave for companies with better work-life balance. Engineers focus on short-term problem-solving rather than long-term strategy or creative thinking under constant stress. This stifles innovation and limits your organization’s competitive position.
Frequent Development Bottlenecks
Bottlenecks drag out timelines and delay value delivery. They increase the financial burden of every sprint. McKinsey found that 66% of large IT projects run over budget, and 70% deliver late. Developers sit idle or spend time on low-value tasks instead of building software when decisions stall or dependencies block progress.
Performance bottlenecks compound as usage scales. A 1-second page delay can reduce conversions by 7% in high-growth environments. CPU saturation or inefficient queries can turn scaling costs exponential, especially for teams that lack clear SaaS scalability strategies for sustainable growth. Teams spend more time firefighting and less time shipping. The roadmap slips. Technical debt accumulates.
Expansion Of Product Features Or Markets
Your roadmap that expands to more platforms just needs specialized engineering expertise to develop and maintain the product across different environments, including carefully planned cloud migration for growing teams when infrastructure must evolve. Skills gaps within the current team result in limitations for executing certain aspects of product development. Bringing in additional engineers with necessary technical skills addresses these capability gaps.
Too many high-priority initiatives for one team to handle signals the need for parallel work streams. Cycle times that increase despite more engineers indicate structural problems rather than simple capacity issues. Misalignment between product, design, and engineering creates friction that slows delivery whatever the team size.
Key Challenges Companies Face During Scaling Engineering Team
Scaling engineering team brings opportunity, but it also introduces new operational pressure. As the engineering organization expands, communication patterns change and processes become more complex. Leaders must manage hiring, maintain code quality, and support engineers while the team grows, often benefiting from tech consulting services that help modern businesses grow to design the right operating model. Without structure, rapid growth can quickly create inefficiencies across projects and teams.
Communication Complexity Across Teams
Growth increases communication overhead. A study from Harvard Business Review shows that communication channels grow exponentially as more people join a team. A group of 5 engineers has 10 communication paths. A team of 15 engineers has 105. Coordination quickly becomes difficult.
Engineering leaders often notice slower decisions when the engineering team expands. Engineers spend more time answering questions and less time building software. Clear ownership and well-defined projects reduce confusion. Design docs and architecture reviews also help engineers share context with other teams and reduce unnecessary meetings.
Code Quality And Technical Debt
Rapid growth often creates pressure to ship a new feature quickly. Teams sometimes skip code review or testing steps to reduce lead time. Over time, this approach increases technical debt and other hidden costs in software development. McKinsey reports that technical debt can consume up to 40% of engineering time in many companies.
Strong engineering culture helps maintain code quality during scaling engineering. Clear coding standards and structured code review protect system reliability. Engineering leaders must also support engineers with internal tools and architecture reviews. A healthy engineering organization balances speed and quality across projects.
Hiring And Talent Bottlenecks
Engineering talent remains difficult to find. According to the U.S. Bureau of Labor Statistics, demand for software engineers is expected to grow 25% from 2022 to 2032. Most companies compete for the same talent pool.
A structured interview process helps hiring managers maintain a consistent hiring bar. Engineering leaders must evaluate skills, culture fit, and collaboration ability. Senior engineers often join the interview process to answer questions and evaluate candidates. A strong hiring process ensures that new hires strengthen the engineering team rather than slow it down and align with realistic software development timelines for different project types.
Knowledge Gaps And Tribal Knowledge
Early-stage teams often rely on tribal knowledge. Founders or senior engineers hold key system knowledge inside their heads. As more engineers join the organization, this knowledge gap becomes risky.
Clear documentation solves this issue. Design docs, architecture reviews, and internal tools help share knowledge across the engineering organization. Engineers should spend time documenting systems and trade offs. Clear documentation reduces cognitive load for new engineers and allows other teams to understand complex systems.
Team Structure And Ownership Issues
Growth changes the structure of an engineering organization. A single team that once built the entire product eventually splits into multiple teams. Without clear ownership, engineers may duplicate work or create conflicting systems.
Engineering leaders must identify clear ownership across projects and systems. Cross-functional teams often help larger companies manage complexity. Each team focuses on a specific area while still collaborating with other teams. Clear structure allows engineers to move faster and reduce coordination delays.
Maintaining Engineering Culture
Culture often weakens when the engineering team grows quickly. New hires join with different expectations and work habits. Without strong leadership, company culture can drift.
Engineering leaders must define clear expectations early. Regular performance reviews, mentorship, and internal mobility help maintain culture. Teams that share values around code quality, collaboration, and knowledge sharing create a positive experience for engineers. A strong engineering culture helps organizations scale while keeping teams motivated and aligned.
Hiring Strategies To Scale Engineering Team
Building the right hiring process determines whether scaling engineering team accelerates or stalls your organization. Research shows that HR teams who implement analytical recruitment are twice as likely to find talent efficiently.
Structured Technical Hiring Framework
Standardized assessment creates fairness and consistency that benefits both candidates and your engineering organization. Structured hiring uses clearly defined role requirements, consistent assessment criteria, and standardized interview questions. Ad-hoc interviews where expectations change between interviewers become a thing of the past.
GitLab faced this challenge during hypergrowth. Candidates received different interview formats depending on their interviewer. This led to inconsistency and bias. Some interviewers assessed more strictly than others. The solution involved creating predefined interview projects with rubrics segmented into categories like testing. Each category had specific task objectives and point values. Engineering leaders could then objectively determine whether candidates would pass based on tabulated scores.
Analytical Candidate Assessment
Facts replace gut feelings when you implement objective assessments. Companies using psychometric assessments make more reliable hiring decisions, with 81% now incorporating these tools. Analytical candidate assessment gathers valuable information about track record, skills, potential, and behavior.
General mental ability tests predict job performance better than most other factors. Predictive validity increases further when paired with work sample tests, integrity tests, or structured interviews. The key is ensuring assessments are created and validated as scientific instruments that reduce bias.
Track metrics like time to hire, cost to hire, and acceptance rates to measure your hiring process quality. Technology and advanced analytics, including AI-powered software tools that simplify day-to-day work, reduce time spent assessing candidates while minimizing human error.
Balanced Hiring Across Experience Levels
Senior engineers bring experience that prevents costly mistakes. They structure systems for long-term stability and scale efficiently. They handle unexpected complications. Senior talent ensures your foundation stays solid for complex projects requiring strong backends or tight security.
Junior engineers become valuable once you have 2-3 senior engineers who can mentor them. The magic ratio sits around 1 junior for every 2-3 senior engineers. Junior talent provides fresh views and budget-friendly growth. They build your future talent pipeline.
Start small with 1-2 junior engineers and measure how quickly they become productive. Invest in mentoring infrastructure and create clear learning paths, supported by flexible custom software solutions that match your workflows. Be patient with short-term productivity. The long-term payoff justifies the investment.
Culture Fit And Working Together Focus
Leadership IQ reveals that 89% of hiring failures occur due to poor cultural fit, not lack of technical skills. Companies with strong cultural fit see 20-25% lower turnover rates. Cultural alignment between employees leads to smoother teamwork and higher workplace efficiency.
Culture fit means finding professionals who arrange with your core values while bringing diverse views. Assess values alignment, communication style, teamwork priorities, and growth mindset through behavioral interview questions. Ask candidates to describe times they disagreed with team decisions or worked with non-technical stakeholders.
Skills-based hiring is the future, with 75% of HR professionals prioritizing this method. Balance technical assessments with culture assessment to build cohesive teams that can take advantage of AI software development for smarter digital products.
Continuous Engineering Talent Pipeline
Hiring to fill today’s gaps costs time and momentum. Build relationships with engineers early by sharing resources like the GainHQ software development and digital transformation blog and encouraging your team to speak at conferences. Create communities around your engineering organization.
Keep candidates warm even when they’re not the right fit right away. Companies with strong employer brands are three times more likely to make quality hires. Stay connected through industry information, webinars, and events.
Skills-based hiring expands talent pools by six times. Focus on what individuals can do rather than only titles or qualifications to open doors to hidden talent globally.
Team Structure Models For Scaling Engineering Team Efficiently
Team structure choices determine whether your engineering organization scales smoothly or collapses under coordination overhead. The models you select should match your product architecture, company stage, and the type of work engineers perform daily.
Cross-Functional Product Squads
Spotify’s squad model demonstrates how small autonomous groups deliver software without red tape. Each squad has developers and a product owner working on a specific functional area. The squads release work to market without consulting stakeholders and eliminate bottlenecks that slow traditional organizations.
Cross-functional teams start with program management to identify components. Product managers then connect requirements while engineering leads assess technical feasibility. UI engineers, database engineers, and media engineers write user stories. QA engineers test implementation and release management handles deployment.
Platform And Infrastructure Teams
Platform teams provide internal products that other teams consume via self-service APIs and golden paths. They own platform building blocks like CI/CD pipelines, observability, Identity and Access Management, and Infrastructure as Code.
These teams focus on shared technology that delivers capabilities to other teams. Subsystem teams handle expert-level skills around technologies requiring specialized experience. Platform engineers split into DevEx engineers who understand developer pain points and infrastructure engineers who help with compliant resource consumption.
Feature-Based Engineering Teams
Feature teams work on end-to-end customer features with full-stack individuals spanning different system areas. These long-lived teams typically have one project manager, one designer, and two to ten developers or testers.
Feature teams accelerate value delivery by focusing on user needs. They shorten feedback loops from actual users and reinforce disciplined MVP feature prioritization to build the right product. They excel when employees work full-stack, customers want optimized lead times, and organizations prioritize the most valuable items.
The optimal mix combines 75-80% feature teams with 20-25% component teams. Feature teams bank on agile efficiency. Component teams contribute technical integrity by building reliable and reusable components.
Domain-Based Engineering Teams
Domain-based structures organize squads around business subdomains rather than arbitrary divisions. Each domain gets a domain lead responsible for success alongside the product manager and domain contributors who participate in planning and implementation.
This approach creates multiple technical leadership opportunities per squad instead of one. It reduces meeting time and eliminates single points of failure. Engineers spend 50% less time in meetings when domains divide squad efforts. Knowledge sharing increases while the bus factor drops because multiple engineers cooperate within each domain, similar to how Minimum Viable Products in software development consolidate learning around clear problem domains.
Processes And Tools For Scaling Engineering Team Growth
Processes and tools create the operating system for your engineering organization. Engineers lose up to 20% of their time navigating toolchain complexity due to fragmented systems. Tool consolidation, including the adoption of smarter AI-powered software tools, becomes one of the highest-ROI levers for restoring flow during rapid growth.
Standardized Development Workflows
Different teams building their own testing and deployment methods causes confusion when developers move between projects. Standardization does not mean forcing similar tools. You should agree on common practices for deployments, test execution and service monitoring. This consistency helps new engineers get comfortable faster because workflows feel familiar.
Strong Documentation And Knowledge Sharing
Knowledge transfer breaks down for two reasons: knowledge is scattered and documentation is outdated. Project-specific knowledge has design decisions, architecture choices and component interactions that accumulate over time. This knowledge lives in developer minds, code comments, Wiki pages, Slack conversations and emails. Finding it becomes very hard. Developers spend precious time locating and updating documentation. Outdated docs erode trust and create a vicious cycle.
Clear Engineering Leadership Structure
Engineering organizations require different leadership as the team grows. You must clarify information sharing between roles and departments early. Use cross-team meetings, shared documentation and project tracking tools.
Automation In Testing And Deployment
Developers using CI/CD tools are 15% more likely to be top performers. Automation reduces deployment times from months to hours and enables multiple daily updates, which is critical for following emerging MVP development trends for startups in 2026. Automated tests provide instant feedback. Developers can address issues quickly.
How GainHQ Supports Companies In Scaling Engineering Teams
GainHQ helps companies scale engineering team with structured systems, clear workflows, and modern tools. The platform centralizes tasks, discussions, and documentation so the engineering team stays aligned on priorities and projects. Engineers, managers, and other teams work with the same information, which reduces confusion and improves collaboration across the engineering organization.
Clear visibility helps engineering leaders manage growth with confidence. Teams can connect customer feedback, feature requests, and development tasks in one place. This structure helps engineers focus on building software rather than searching for information. Consistent workflows also improve code quality and reduce delays when the team grows.
GainHQ also supports scalable software systems and custom internal tools that help companies manage rapid growth. Organizations gain the tools, structure, and engineering talent support needed to build strong engineering culture and scale their engineering organization successfully.
FAQs
Can A Small Engineering Team Scale Without Hiring Many Engineers?
Yes. A small engineering team can scale output by improving processes, internal tools, and automation. Engineering leaders often reduce lead time through better code review practices, design docs, and clear ownership. Efficient systems allow the existing team to deliver new feature updates without immediately adding more engineers.
Does Remote Engineering Team Structure Affect Scaling Engineering Team?
Yes. Remote engineering teams require stronger documentation, clear communication, and structured workflows. Engineering leaders often rely on design docs, internal tools, and architecture reviews to reduce cognitive load. Strong engineering culture ensures engineers across locations collaborate effectively while the engineering organization continues to scale.
What Metrics Help Engineering Leaders Track Scaling Engineering Team Success?
Engineering leaders often track lead time, deployment frequency, and defect rate to evaluate scaling engineering progress. Other metrics include engineering team productivity, code quality, and time spent resolving technical debt. These indicators help companies identify whether the engineering organization scales efficiently.
Is Internal Mobility Helpful When Scaling Engineering Team?
Yes. Internal mobility helps companies use existing engineering talent more effectively. Engineers move across projects or other teams based on skills and experience. This approach reduces hiring pressure, spreads knowledge, and strengthens collaboration across the engineering organization.
How Do AI Tools Support Scaling Engineering Team?
AI tools support scaling engineering by automating repetitive development tasks. Engineers use AI tools for code suggestions, debugging, and documentation support. These tools reduce cognitive load, improve productivity, and allow engineering teams to focus more on building software and solving complex problems, similar to how a startup leveraged them in an MVP launch case study completed in 90 days.
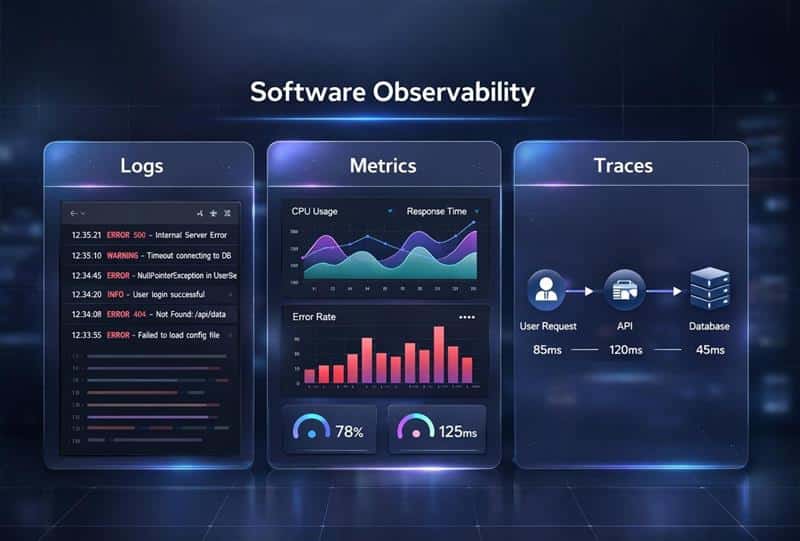
Software observability delivers strong returns. Many teams report a 4x ROI after adopting modern observability platforms. High-growth SaaS companies that run distributed systems need deep visibility into system behavior and system performance. Modern software systems produce massive telemetry data every second. Logs metrics and traces flow from multiple services, infrastructure components, and cloud native applications. Observability tools provide a way to collect data, analyze data, and understand system health in real time.
Modern observability goes beyond traditional monitoring tools. It helps development teams correlate data across cloud infrastructure, serverless functions, and distributed tracing pipelines. Observability platforms provide analysis capabilities that turn operational data into actionable insights. Teams can detect performance bottlenecks, analyze log data, and complete root cause analysis faster. Strong observability solutions improve system reliability, support digital transformation, and strengthen application performance across complex cloud native environments.
What Is Software Observability
Software observability helps teams understand what happens inside modern software systems. It focuses on collecting and analyzing telemetry data such as logs, metrics and traces. Observability tools provide deep visibility into system behavior, system health, and application performance. Instead of only tracking surface-level performance metrics like CPU usage, teams analyze data across distributed systems and multiple services. Observability data reveals how a user request moves through complex systems in cloud computing environments.
Modern observability goes beyond traditional monitoring tools. Observability platforms provide analysis capabilities that help development teams correlate data from infrastructure components, cloud native applications, and serverless functions. By analyzing observability data, software engineers can detect performance bottlenecks and complete root cause analysis faster. Strong observability solutions improve system reliability and support the full software development lifecycle in complex cloud native environments.
Observability vs. Traditional Monitoring
Modern software systems run on distributed systems, cloud native applications, and multiple services. Many teams still rely on traditional monitoring tools. Monitoring tracks system health, but software observability goes deeper. It explains system behavior and reveals hidden risks inside complex systems, which is crucial when designing scalable, secure SaaS architectures.
Scope Of Data Collection
Traditional monitoring focuses on predefined performance metrics. Teams track CPU usage, memory, uptime, and error rates. Monitoring presumes you already know what might go wrong.
Software observability collects broader telemetry data. Observability tools gather logs metrics and traces across infrastructure components and cloud infrastructure. Observability platforms provide a unified observability platform that correlates operational data. Teams can analyze data beyond preset dashboards.
Known Unknowns Vs Unknown Unknowns
Monitoring can only track known unknowns. Teams define alerts in advance and wait for system events. That approach worked well for legacy systems.
Distributed systems create unpredictable behavior. Observability enables teams to explore unknown unknowns. Engineers analyze log data and distributed tracing paths without predefined assumptions. Complex system behavior becomes easier to understand in cloud native environments.
Causes Of The Problems
Traditional monitoring provided adequate visibility into legacy infrastructures. It shows what failed but struggles to explain why a problem exists. Alerts often lack context.
Software observability supports deep root cause analysis. Observability data connects user request paths with application performance. Teams correlate data across system components. Analysis capabilities help explain performance regressions, outages, and even security threats.
Depth Of Exploration
Monitoring typically checks system health through preset dashboards. It focuses on surface-level signals. Application performance monitoring tools often stop at thresholds.
Observability takes monitoring to the next level of insight. Observability platforms provide context across logs and traces, performance data, and user behavior. Splunk reports that organizations with mature observability resolve incidents 2.5 times faster. Deeper exploration improves system reliability and application performance management.
Role In Modern DevOps
Monitoring supports alerts and basic performance monitoring. It remains useful and does not disappear. Observability does not replace monitoring tools. It expands their value.
Observability empowers engineering teams and DevOps teams to manage complex environments. Modern observability improves digital transformation outcomes and cloud migration success for growing teams. Gartner notes that over 70% of enterprises now prioritize observability solutions for cloud native systems. Strong observability software strengthens the entire software development lifecycle.
Observability Vs Traditional Monitoring Comparison Table
Criteria
Traditional Monitoring
Software Observability
Primary Focus
Tracks predefined performance metrics such as CPU usage, memory, uptime
Examines overall system behavior across complex systems
Data Scope
Collects preset data points
Collects broad telemetry data including logs metrics and traces
Visibility Level
Surface-level system health checks
Deep visibility into distributed systems and multiple services
Problem Detection
Identifies known unknowns based on configured alerts
Detects unknown unknowns through analyzing observability data
Root Cause Analysis
Limited context, often requires manual investigation
Supports faster root cause analysis with correlated data
Architecture Fit
Works well for legacy systems
Designed for cloud native environments and distributed tracing
Data Correlation
Siloed monitoring tools with limited cross-system correlation
Unified observability platform that correlates operational data
Exploration Capability
Relies on predefined dashboards
Enables flexible exploration of logs and traces and performance data
DevOps Impact
Supports basic performance monitoring
Empowers engineering teams to optimize system reliability
Business Context
Focuses on infrastructure-level signals
Connects application performance with user behavior and business impact
How Observability Solves Critical SaaS Performance Issues
Observability platforms change how teams handle performance challenges. The data collected through logs, metrics and traces helps engineering teams diagnose issues faster and prevent problems before users notice them, which is essential for executing SaaS scalability strategies for sustainable growth.
Fast Root Cause Analysis
Root cause analysis identifies the mechanisms of problems rather than addressing symptoms. Observability software accelerates this process through unified data correlation. Organizations that adopt observability see up to 54% reduction in mean time to resolution.
Related data streamlines troubleshooting. An API that experiences latency spikes can be analyzed with observability tools that relate logs, metrics and traces to pinpoint whether a specific microservice, database query or third-party integration caused the slowdown. This eliminates guesswork by exposing interactions between components and dependencies that might otherwise go unnoticed.
Distributed systems present unique challenges for root cause analysis. A payment processing failure might stem from a timeout in a downstream inventory service. Observability data reveals these connections by visualizing the transaction path in full. Teams can isolate faulty components instead of manually searching through disconnected logs.
Proactive Issue Detection
Proactive monitoring keeps up with trends by looking for early indicators. Observability tools help teams detect and resolve performance problems before they affect customers. Organizations with complete observability practices see 64% fewer incidents that could potentially affect users.
Establishing performance baselines based on historical data is foundational. Baselines provide a reference point for labeling data points as anomalies or observing trends. Patterns of subpar or worsening response times found through monitoring almost always indicate serious problems once baselines exist.
End-To-End Request Visibility
Distributed tracing tracks requests as they move through distributed systems. This capability provides insights into system interactions across multiple services and applications. Teams can determine which services are involved in achieving requests and measure how long each service takes to handle its part.
End-to-end tracing monitors request status from initiation through completion. The tracing platform creates a unique trace ID and tracks the request through frontend to backend when a user submits a form. Each step generates a span representing a single unit of work, such as an API call or database query.
Key Benefits Of Software Observability
High-performance teams adopt observability software for measurable business outcomes. 58% of organizations receive $5 million or more in total value from their observability investment each year. Teams report a median return on investment of 295%. Every dollar spent returns four dollars of value.
Low Mean Time To Resolution
Observability platforms cut incident resolution times. Organizations with complete observability practices reduce mean time to resolution by up to 54%. This acceleration comes from autonomous reasoning, correlation and actioning capabilities that compress investigation timelines from hours to minutes.
Traditional incident investigation relies on manual log analysis and tribal knowledge. Observability tools automate routine diagnostics so engineering teams focus on software development instead of endless troubleshooting. Site reliability engineers query logs, get into visualizations and relate traces to find root causes faster.
Better System Reliability And Uptime
System uptime affects revenue and customer trust. Research shows 46% of organizations report that observability improved system uptime and reliability. Live visibility shifts operations from reactive firefighting to proactive prevention and minimizes downtime.
The financial stakes are substantial. Unplanned downtime costs reach $5,600 to $9,000 per minute across industries. Every grounded aircraft hour costs airlines between $10,000 and $15,000, not including hotel vouchers, rebooking expenses and customer attrition. Companies with optimized mean time to resolution cut downtime costs by up to 30%.
Analytical Decision Making
Observability data informs strategic business decisions beyond technical troubleshooting. Teams gain specific details to optimize investments and understand fluctuations of digital business performance in real time. Tracking user behavior helps organizations identify functionalities that users access most and areas where users encounter issues.
Predictive analytics use historical data and machine learning algorithms to forecast future trends. Organizations anticipate resource needs during peak periods and avoid overages while maintaining budget discipline. This capability transforms approaches from reactive responses to proactive strengthening, especially when supported by dedicated predictive analytics software platforms.
Optimized Resource Use
Observability tools uncover inefficiencies in resource usage through granular insights into CPU, memory and GPU consumption. These insights inform strategic workload placement and dynamic resource allocation in a cloud-first SaaS development model. Atlassian reduced metrics data costs by 10% using Splunk’s metrics pipeline management capabilities.
Teams identify overprovisioned resources and underutilized assets that waste compute power or storage. Observability platforms help DevOps and business teams combine disparate tools and improve cost efficiency with capacity planning. Organizations automate scaling policies to allocate resources during peak hours and reduce allocation afterward. This avoids overprovisioning.
Essential Observability Tools And Platform Capabilities
Observability platforms that work integrate multiple capabilities and provide unified visibility across distributed systems. These platforms collect telemetry data from infrastructure components, applications and user interactions.
Infrastructure Monitoring Features
Infrastructure monitoring tools track performance and health across servers, containers, databases and cloud resources. Agent-based collection installs lightweight software on hosts and gathers detailed metrics about CPU usage, memory utilization, network bandwidth and disk space. These agents find components on their own and capture data at one-second intervals without sampling.
Agentless monitoring relies on built-in protocols like SNMP and SSH and collects system data without additional software installation. Cloud-native support proves critical for modern systems. Platforms integrate with third-party cloud providers and track ephemeral resources as they scale on their own.
Tagged infrastructure metrics apply metadata like operating system, service name or availability zone to backend components. These tags let teams total metrics across infrastructure and identify specific areas experiencing issues. Machine learning capabilities analyze historical performance and detect anomalies on their own.
Distributed Tracing Capabilities
Distributed tracing tracks requests as they flow through multiple services in microservices architectures. Each activity generates a span with timestamps and metadata. These spans assemble into complete traces that show the full request timeline.
OpenTelemetry provides industry-standard instrumentation for vendor-neutral trace collection. Auto-instrumentation libraries enable zero-code setup for popular languages and frameworks. Service maps visualize dependencies between components. Flame graphs display parent and child spans and reveal bottlenecks.
Log Management And Analysis
Log management tools collect, process and analyze log data from applications and systems. Ingestion handles both structured JSON and unstructured text formats in real time. Advanced search and filtering capabilities let teams query logs fast and find relevant information.
Centralized platforms total logs from multiple sources into unified views. Parsing extracts meaningful patterns from large volumes of log data on its own. Customizable dashboards provide visualizations that help teams monitor key metrics and reduce manual work.
Real-User Monitoring Integration
Real-user monitoring captures actual user interactions with web browsers and mobile applications. The technology tracks client-side performance metrics that include Time to First Byte, page load times and JavaScript errors, which directly influence UX-driven churn reduction and retention.
RUM agents are framework-agnostic and work with any frontend application. They measure user behavior, screen load times and platform-specific issues like Android ANR events. Integration with distributed tracing connects frontend experiences to backend service performance, complementing specialized UI/UX design services for SaaS products.
Best Practices For Implementing Observability Software
Modern software systems grow fast. Distributed systems, cloud native applications, and multiple services create complex environments. Software observability becomes a critical capability in this setup. A clear strategy helps development teams improve system reliability, detect performance bottlenecks, and maintain strong application performance across the software delivery lifecycle.
Define Clear Observability Goals
Every observability strategy needs direction. Engineering teams must define what system behavior they want to measure. Focus on key performance indicators such as latency, error rate, throughput, and CPU usage. These performance metrics connect directly to system health and user behavior.
Research from Google’s DORA reports shows elite teams deploy 973 times more frequently than low performers. Clear goals help correlate data with business outcomes. Observability tools provide better results when teams align observability data with system reliability and user request performance.
Collect High Quality Telemetry Data
Software observability depends on telemetry data. Modern systems generate logs metrics and traces across infrastructure components and cloud infrastructure. Data collection must stay consistent across multiple services and distributed systems.
Observability platforms provide structured pipelines for metrics logs and traces. Poor data quality leads to weak root cause analysis. Gartner reports that poor data quality costs organizations an average of $12.9 million per year. Strong telemetry data types improve actionable insights and performance data accuracy.
Unify Logs Metrics And Traces
Siloed monitoring tools slow teams down. Observability solutions must unify logs and traces with metrics logs and traces in one unified observability platform. Distributed tracing connects system events across cloud native environments.
Observability platforms provide correlation across operational data. Teams can analyze log data alongside performance monitoring signals. According to Splunk’s State of Observability report, 83% of organizations say unified observability reduces mean time to resolution. Faster analysis capabilities improve system performance and reduce unknown unknowns.
Integrate Observability Early In Development
Software observability should start inside the software development lifecycle. Development teams must integrate observability into continuous integration pipelines and cloud migration strategies. Early visibility improves application performance management.
McKinsey reports that organizations with mature observability reduce downtime costs by up to 50%. Observability tools provide early feedback during software development. Engineers detect performance bottlenecks before release. Strong integration supports digital transformation and software modernization for legacy systems and strengthens system components across complex cloud native applications.
Use Automation And Predictive Analytics
Modern observability platforms use machine learning algorithms to analyze data at scale. Predictive analytics helps detect security threats and performance issues before users notice them, especially when combined with broader AI-driven automation in SaaS platforms. Control theory concepts also support automated system reliability improvements, especially when combined with consistent SaaS design systems for scalable products.
Gartner predicts that by 2027, 40% of organizations will adopt AI-driven observability solutions. Observability platforms provide proactive alerts based on telemetry data and system events. Engineering teams gain faster root cause analysis and stronger application performance without manual effort.
Focus On Business Impact And User Experience
Observability data must connect to user interface performance and user behavior. A slow user request directly affects revenue. Amazon once reported that every 100ms delay in page load time reduced sales by 1%. System performance matters.
Observability tools provide visibility into application performance across cloud native environments and serverless functions. Teams can correlate data between system components and customer experience metrics. Strong observability software supports system reliability, protects revenue, and strengthens long-term digital transformation goals.
Common Problems Of Software Observability
Software observability delivers strong value, yet many organizations struggle during implementation. Modern systems generate massive telemetry data across distributed systems and cloud native environments. Complex technology stacks add friction. Many organizations also depend on rigid off-the-shelf tools where custom software can transform operations. A strategic shift beyond traditional monitoring becomes necessary for long-term success.
Alert Fatigue And Noise
Observability tools can flood teams with alerts. Alert storms often hide critical system events. Gartner reports that over 30% of outages escalate due to missed alerts. Static thresholds increase noise in complex systems.
Solutions:
Base alerts on SLOs instead of static thresholds
Use AIOps and machine learning to detect anomalies
Prioritize alerts tied to user request and system reliability
Data Volume And Cost Control
Modern software systems produce huge volumes of logs metrics and traces. Observability data grows fast in cloud computing environments. High data collection costs reduce ROI. Controlling telemetry data types becomes difficult at scale.
Solutions:
Implement intelligent sampling for distributed tracing
Apply strict data retention policies
Track performance metrics that link to business value
Complex Technology Stacks
Distributed systems span multiple services, cloud infrastructure, and serverless functions. Engineering teams struggle to correlate data across system components. Observability platforms provide visibility, but integration across modern systems requires planning.
Solutions:
Deploy a unified observability platform
Standardize telemetry data formats across infrastructure components
Host the observability stack separate from production systems
Manual Instrumentation Gaps
Some frameworks and legacy code lack native observability support. Manual instrumentation increases effort during software development. Software engineers must modify code to collect data and capture system behavior.
Solutions:
Prioritize auto-instrumentation where possible
Document telemetry standards inside the software development lifecycle
Focus manual instrumentation on high-risk complex systems
Slow Insight From Raw Data
Raw operational data alone does not create value. Laborious analysis of logs and traces delays root cause analysis. McKinsey notes that poor observability maturity can increase downtime costs by up to 40%.
Solutions:
Use observability platforms with strong analysis capabilities
Correlate performance data with user behavior
Leverage predictive analytics for faster actionable insights
Software observability requires more than new monitoring tools. A strategic shift toward active introspection across cloud native environments helps teams unlock real value from observability solutions.
How GainHQ Strengthens Software Observability For Modern SaaS Teams
Modern SaaS teams manage distributed systems across cloud infrastructure and multiple services. Software observability becomes critical in such complex environments. GainHQ helps engineering teams gain better visibility into system behavior and system performance. It supports structured data collection across workflows and infrastructure components. Teams can track key performance metrics and monitor system health without relying only on traditional monitoring tools.
Observability tools provide deeper insight when connected to business workflows. GainHQ improves how teams analyze data across the software development lifecycle. Clear operational data helps detect performance bottlenecks and improve system reliability. The same disciplined approach that helped a SaaS startup launch an MVP in 90 days applies when embedding observability from day one, especially when teams follow a structured guide to building a minimum viable product in software development. With better visibility into application performance and user request flows, teams strengthen cloud native environments and build more resilient modern software systems.
FAQs
Can Software Observability Reduce Cloud Infrastructure Costs?
Yes. Software observability helps teams analyze data across cloud infrastructure and detect unused resources. Clear visibility into telemetry data, CPU usage, and performance metrics supports smarter scaling decisions and prevents overprovisioning in cloud native environments.
Is Software Observability Necessary For Small SaaS Startups?
Yes. Even small teams run distributed systems and multiple services. Observability tools provide early insight into system behavior and application performance, which protects system reliability during rapid growth and cloud migration.
Does Software Observability Improve Security And Compliance Monitoring?
Yes. Observability platforms provide deeper visibility into system events and operational data. Teams can correlate logs, metrics and traces to detect unusual user behavior and potential security threats across infrastructure components.
Can Observability Platforms Work With Hybrid Or Multi Cloud Environments?
Yes. Modern observability solutions collect telemetry data types from multi-cloud infrastructure and cloud native applications. A unified observability platform helps engineering teams maintain consistent system health across complex environments.
How Does Software Observability Support Continuous Integration Pipelines?
Software observability connects performance data with the software development lifecycle. Development teams gain real-time insight into system performance during releases. Faster feedback improves application performance management and reduces production risks.
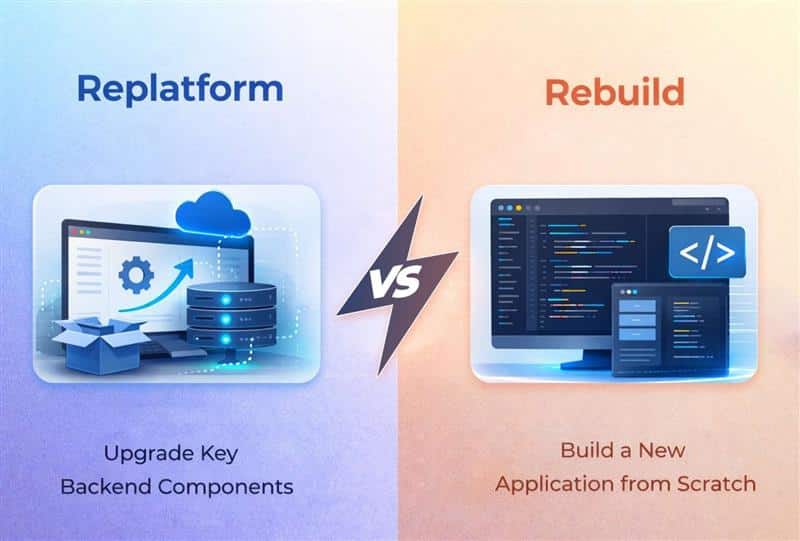
Replatform vs rebuild decisions shape how businesses prepare their technology for long term platform growth. Many organizations operate on outdated platforms that struggle to meet today’s demands for speed, scalability, and reliability. As systems age, companies must decide whether to make minimal changes through replatforming or invest in completely rebuilding their applications for a fresh start.
Choosing the right path often depends on resources, risk tolerance, and strategic priorities. A new platform can unlock modern capabilities, improve performance, and reduce long term maintenance challenges. However, rebuilding an application completely can be resource intensive and requires careful planning to avoid costly delays. When approached strategically, both options help businesses cut costs over time, strengthen operational stability, and create a foundation that supports future innovation and growth.
Why Teams Struggle With Replatform Vs Rebuild Decisions
Imagine a SaaS product launched around 2015. Back then, the tech stack was solid. The product found its market, gained customers, and grew steadily. Now, a decade later, the reality looks different. Hosting bills keep climbing. Performance issues appear during traffic peaks. Feature delivery takes twice as long as it should.
Product leaders usually balance three pressures at once. Keep customers happy this quarter. Cut infrastructure waste. Make sure the product is not stuck on tech that will be obsolete by 2028. These competing demands create a difficult environment for making long term decisions about legacy system modernization.
Legacy systems built on stacks like .NET Framework on Windows Server 2012 or PHP apps tied to on-prem MySQL often block simple things. Single sign-on becomes a challenge. Modern analytics integration feels impossible. Usage-based pricing requires workarounds that add more technical debt to an already strained codebase.
This is where the real question appears. Should you replatform your app to a modern foundation, or rebuild the whole thing from scratch? The answer is rarely obvious. Both two strategies have their place, and choosing between replatforming and rebuilding requires honest assessment of where you are and where you need to go.
What Replatforming Means In Practice
Replatforming means moving your existing application to a newer runtime platform or cloud environment while keeping most of the business logic and user flows intact. Think of it as giving your product new life without completely rethinking its foundations.
Consider a concrete example. A monolithic ASP.NET app running in an on-premise data center since 2016 gets moved to Microsoft Azure App Service in 2026. Or a LAMP stack shifts to containerized workloads on AWS ECS or Kubernetes. The application code stays largely the same. The infrastructure underneath transforms completely.
Typical modernization moves during a replatforming project include upgrading the database engine version, adopting managed services for caching and storage, and wiring in DevOps pipelines. You might also enable lifecycle policies for better resource management or migrate to cold storage tiers for archived data. These common modifications happen without rewriting every feature.
Users often see the same screens and URLs after replatforming. The product feels faster, more stable, and supports integrations that were not realistic on the old infrastructure. Your team gains operational efficiency while customers experience better performance and reliability.
Key Characteristics Of Replatforming
Replatforming focuses on changing the “where” and “how” the app runs, not the core “what” it does. The existing architecture remains largely intact while the runtime platform evolves.
Most of the existing codebase stays the same. Teams make targeted changes around configuration, data access, and integrations to fit cloud native services like PostgreSQL, Redis, or message queues. Minimal code changes keep the project scope manageable.
Projects often run between 3 and 9 months for a mid-sized SaaS product. Staged cutovers keep downtime within defined maintenance windows, ensuring minimal disruption to your customers and business units.
Cost is typically lower than a complete rebuild because teams reuse business rules, workflows, and domain knowledge already captured in the code and database. The migration process leverages your investment in the existing codebase rather than discarding it.
The biggest risks center around missed dependencies, performance regression in the new environment, and underestimating data migration complexity. Careful planning and thorough testing help mitigate these concerns.
When Replatforming Is The Better Move
Several real-world signals point toward replatforming as the best path forward.
Your product still fits the market well. Customer churn stays low. But infrastructure incidents keep increasing quarter after quarter. Site speed degrades under load. Support tickets about reliability pile up.
Regulations or customer contracts may require better availability or data residency. Moving to a compliant cloud region solves the issue without a full rewrite. You can take advantage of public cloud capabilities for high availability and security compliance.
If your team needs faster deployment, better observability, and the ability to experiment with new features, but the main feature set remains valid, replatforming is usually the smarter first step. It represents a low risk path to modernization.
Consider a B2B SaaS with 500+ customers. The company needs to add modern billing and analytics capabilities. Rather than pausing everything for an 18 month rebuild, replatforming lets them ship improvements while protecting existing revenue streams.
How To Keep Replatforming Costs Under Control
Start with a short assessment phase of 3 to 4 weeks. Document current infrastructure spend, peak traffic patterns, and critical integrations before locking any cloud architecture. Inventory applications and their dependencies thoroughly.
Use managed database, caching, and storage services instead of self-managed clusters where possible. Managed services reduce operational overhead in the first 12 to 24 months and help control costs over time.
Prioritize a small set of performance and reliability goals. Aim to reduce average response time by 40 percent or cut unplanned downtime below 4 hours per year. Clear targets help teams stay focused and avoid scope creep.
Ship replatforming in phases by grouping modules or tenants. Teams can roll back if needed. Phased approaches avoid the high risk, big bang switch that can derail projects.
One SaaS company reduced their monthly infrastructure costs by 35 percent by moving to managed services and implementing ARM templates for consistent deployments. They completed the replatforming in 5 months with zero unplanned downtime.
What Rebuilding Really Involves
Rebuilding is not just a “bigger refactor.” It represents a clean break. You design and code a new product version using modern patterns like microservices architectures, event-driven flows, serverless architectures, or modular monoliths.
Consider a realistic rebuild decision. A ten year old monolithic CRM written in an outdated framework sits at the center of the business. It has no automated testing. International expansion gets blocked. New pricing models cannot be implemented without costly rework.
A rebuild becomes an opportunity to completely rethink user journeys, permission models, data models, and reporting. The product can dramatically change what it feels like for customers. You can address pain points that have accumulated over years.
Unlike replatforming, rebuilds almost always come with new UI and UX, new APIs, and sometimes new data structures. Careful migration plans become essential. The stakes are higher, but so is the potential for transformation.
Key Characteristics Of Rebuilding
Teams start with fresh repositories. They use a contemporary tech stack like React or Vue on the frontend and Node.js, .NET 8, or Go on the backend. The data model gets redesigned to match current and future business needs.
Timelines for serious products often run between 12 and 24 months. Overlapping workstreams cover backend, frontend, data, and migration tools. A minimum viable product might launch earlier, but the full transition takes time.
The risk profile is higher because new bugs and unknown edge cases appear. Teams must support both the legacy and the new system during a transition period. This parallel operation adds complexity and resource demands.
The payoff is a codebase that is easier to test, easier to onboard new developers into, and better suited to experiments like feature flags and A/B testing. Technical debt gets eliminated rather than carried forward. Fresh start means fresh possibilities.
A rebuild represents a significant investment. It requires commitment from internal stakeholders across the organization. But for products with fundamental limitations, it may be the only path forward.
When A Full Rebuild Is Worth It
Several business warning signs indicate rebuilding becomes necessary.
Major features take quarters instead of weeks. Critical security patches cannot be applied because the framework is no longer supported. Security gaps multiply. Integrations get blocked because the API layer cannot be extended safely.
Your company wants to move from single tenant, custom deployments for each client to a multi-tenant SaaS model. This architectural shift is not realistic on the old stack. A rebuild becomes the right strategy.
Product strategy changes significantly. You move from a simple ticketing tool to a full customer service platform. Endless patchwork on legacy applications creates more problems than it solves. Rebuilding aligns the technology with evolving business objectives.
Rebuilds can align with major commercial milestones. Entering new markets. Preparing for enterprise deals with strict SLAs. Getting ready for acquisition due diligence. These inflection points justify the investment.
Look 3 to 5 years ahead rather than just the next quarter. Ask whether your existing architecture can support where the business needs to go.
Keeping Rebuild Costs And Risks Manageable
Start with a clear vision and a lean roadmap. Identify the minimum viable product needed to serve existing customers without downgrading their experience. Validate assumptions early before committing resources.
Use patterns like the strangler fig approach. Build new services around the old core. Gradually route traffic to the new system. Avoid turning everything off in one go. This approach reduces risk while enabling progress.
Invest early in automated testing, observability, and a consistent design system. These foundations let the product grow faster after launch. They prevent the new system from accumulating its own technical debt.
Schedule regular checkpoints with stakeholders every 4 to 6 weeks. Review scope creep, technical decisions, and budget versus outcomes. Use plain language so business leaders and technical teams stay aligned.
Teams that succeed with rebuilds treat the project as a product itself. They ship incrementally, gather feedback, and adjust course. This pragmatic approach separates successful rebuilds from painful ones.
Replatform Vs Rebuild: Side By Side Comparison
You need to compare both options on the dimensions that matter most: speed, cost, risk, and impact on customers. This side by side view helps you make an informed decision.
Dimension
Replatform
Rebuild
Time To First Value
2 to 4 months
6 to 12 months
Total Project Duration
3 to 9 months
12 to 24 months
Impact On Existing Users
Minimal disruption
Requires adaptation period
Change To User Experience
Improve performance, same flows
Complete redesign possible
Long Term Flexibility
Limited by existing architecture
Unlimited, cloud native
Upfront Investment
40 to 60% of rebuild cost
Full rebuild investment
Technical Debt Resolution
Partially addressed
Completely eliminated
Risk Level
Moderate
Higher
Replatforming delivers faster improvements, lighter budget impact, and less disruption to current customers. But it cannot radically change the product. The existing codebase constrains what is possible.
Rebuilding takes longer and costs more upfront. It offers a clean slate for major product evolution and technical flexibility. New revenue streams become possible. Cloud based features and modern architectures unlock new capabilities.
Many teams overestimate the need to rebuild when a well planned replatform plus targeted refactoring can cover 70 to 80 percent of their current pain. A hybrid legacy modernization strategy often delivers the best business value.
A Practical Framework To Decide Between Replatform And Rebuild
Here is a simple, repeatable checklist your product team can use in a week or two of workshops. This framework helps you move from uncertainty to clarity.
Stage 1: Assess Where You Are
Evaluate your current state with honest metrics. Look at uptime over the past 12 months. Check average response times and how they have trended. Count incident frequency and severity. Track infrastructure cost trends since at least 2021.
Identify how many features are blocked by the existing architecture. List integrations that cannot be implemented without major changes. Document security gaps and compliance issues. This assessment grounds your decision in reality rather than assumptions.
Stage 2: Clarify Where You Need To Be
Consider planned features for the next 3 to 5 years. Advanced reporting. AI assisted workflows. Mobile apps. Real time collaboration. Can your current stack support them without massive hacks?
Think about business goals beyond features. Cost reduction. Entering new markets. Scaling to 10x your current users. Supporting enterprise customers with strict requirements. Your legacy modernization strategy must align with where the business is headed.
Stage 3: Score Replatform Vs Rebuild
Rate each option from 1 to 5 on four dimensions: business risk, technical feasibility, budget fit, and time to impact. Involve both technical and non-technical stakeholders in the scoring.
A replatform might score high on budget fit and time to impact but lower on long term flexibility. A rebuild might score high on flexibility but lower on budget fit and speed. The scores create a framework for discussion rather than a definitive answer.
Stage 4: Plan For Hybrid Options
Consider hybrid paths. Replatform first in 2025 to stabilize the foundation. Schedule a targeted rebuild of specific modules like billing or analytics in 2026 to 2027. This phased approach balances risk tolerance with available resources.
Many successful modernization projects combine strategies. Some modules get replatformed. Critical components get rebuilt. The portfolio approach maximizes business value while managing investment efficiently.
How GainHQ Guides Businesses Through Replatform Vs Rebuild Decisions
The team at GainHQ has seen many SaaS products and internal tools struggle with the same replatform versus rebuild dilemma. The challenge rarely has an obvious answer. Context matters enormously.
GainHQ typically starts with a discovery process. The team reviews architecture diagrams. They look at production metrics and current website performance data. They run interviews with product owners, support teams, and a small group of users. This research reveals pain points that surface level analysis misses.
The focus stays on connecting technical options to clear business outcomes. Reducing onboarding time. Cutting error rates in support operations. Unlocking new revenue streams. Enabling cloud adoption that supports growth. Every recommendation ties back to what matters for the business.
GainHQ can help plan phased modernization. The team designs replatforming roadmaps that control costs and reduce risk. They structure rebuilds to protect revenue while the new system gets constructed. Both paths benefit from experienced guidance through the migration process.
Think of GainHQ not as a one-off vendor but as a long term partner. The relationship extends from the first infrastructure move to continuous improvement of workflows and customer experience. Whether you need to replatform or rebuild, the goal remains the same: delivering cost effective solutions that serve your customers and grow your business.
Frequently Asked Questions
Is Replatforming Just “Lift And Shift” To The Cloud?
Pure lift and shift usually means copying the application from one environment to another with almost no changes. Replatforming goes further. It includes targeted optimizations like adopting managed databases, adding autoscaling capabilities, and improving deployment pipelines. Replatforming aims for genuine cloud benefits like reliability, observability, and operational efficiency. The goal is not just moving servers from one data center to another. It is transforming how your application runs to improve performance and reduce maintenance costs.
Can We Replatform Now And Rebuild Later?
Many teams follow this exact path. They replatform first to stabilize costs and reliability over 6 to 12 months. Then they plan a deeper rebuild of critical modules once they have more data and budget. Framing replatforming as buying time makes sense. It reduces risk while your organization learns more about long term product direction. You can use the stabilization period to validate assumptions about what a future rebuild should include.
How Do We Avoid Disrupting Current Customers?
Both strategies can be implemented with careful change management. Feature flags help control rollout. Beta programs let you gather feedback before broad release. Staged rollouts by region or customer segment limit blast radius. Transparent communication about maintenance windows builds trust. Early involvement of support teams and account managers helps catch customer concerns before they turn into churn. The goal is progress without surprising your users.
What Skills Does Our Team Need For Replatforming Or Rebuilding?
Replatforming requires strong DevOps, cloud architecture, and database migration skills. Teams need experience with infrastructure as code, container orchestration, and cloud native services. Rebuilding demands additional capabilities. UX design. Product discovery. Modern application architecture experience. The scope is broader because you are creating something new rather than moving something existing. Be honest about in-house capabilities. A partner like GainHQ can fill gaps in planning, implementation, or change management when internal resources are limited.
How Should We Measure Success After Modernizing?
Track clear metrics that connect to business value. Reduction in hosting and maintenance costs. Improved uptime percentages. Faster page loads and site speed. Quicker release cycles. Customer satisfaction scores. Measure these outcomes at three and six months after go-live. Compare results against the original business case. This comparison reveals whether replatforming or rebuilding delivered the expected value and helps guide future decisions.
Research shows that poor planning contributes heavily to project failures. A realistic software development timeline protects your project from costly delays and budget overruns. In fact, studies confirm that projects with detailed planning phases deliver higher on-time success rates by a lot.
Your software development timeline can range from a few months to over a year, depending on project complexity and scope. We understand that navigating the software development life cycle phases requires strategic planning and clear milestones.
In this article, we will walk you through each software development phase, compare software development methodologies, and provide realistic timeline expectations to revolutionize your development process from backlog to production reality.
What Is A Software Development Timeline
A software development timeline outlines all the tasks and key phases of a software development project. It maps the entire development process from the initial stage to the maintenance phase. The software development timeline defines the analysis phase, design phase, development phase, testing phase, and deployment. It sets realistic expectations, aligns project goals, and helps track progress across the entire project. A typical software development timeline depends on project scope, project complexity, and software development methodology such as agile methodologies or rapid application development.
A development timeline supports project planning, resource allocation, and risk management. The project manager coordinates development teams, software developers, and agile teams to meet project requirements. Each project phase includes unit testing, integration testing, system testing, performance testing, security testing, and user acceptance testing. Regular code reviews, detailed documentation, and technical documentation protect software quality and software’s reliability. User research, market research, user feedback, and data migration ensure software aligns with existing systems and customer satisfaction. Rigorous testing and bug fixes support successful completion and high-quality software running smoothly.
Software Development Life Cycle Phases Overview
The software development life cycle phases give structure to your software development timeline. Knowing each phase helps you estimate realistic timelines and allocate resources for your development project.
Planning And Requirements Analysis
The first stage sets the foundation for your development process. Your project team gathers requirements from stakeholders, customers and end users to understand what the software needs to accomplish. Senior engineers and project managers conduct feasibility studies that cover technical, operational and economic aspects.
You create the Software Requirement Specification (SRS) document at this phase. This document acts as the blueprint for all subsequent development activities. Research shows that 39% of software projects fail due to poor requirements gathering and management. Fixing requirement errors costs 5-10 times more during development than during analysis. Production fixes can cost 50-100 times more.
Your team defines project scope, establishes timelines and allocates resources. Business analysts conduct stakeholder interviews, document analysis and use case development. The planning phase takes up 15-25% of your total project budget.
Design And Architecture
Your team transforms requirements into technical specifications once they are finalized. System architects create both High-Level Design (HLD) and Low-Level Design (LLD) documents. The HLD defines overall system architecture, database design and relationships between modules. The LLD covers individual component logic, API interfaces and database tables.
Your design phase addresses critical decisions about future-proof technology stack selection, component identification and integration strategy. Teams create wireframes, data flow diagrams and user interfaces to map out system functionality. UI/UX design makes the software easy-to-use and meets user expectations.
Development And Coding
This is the longest phase where actual building takes place. Developers write code based on the Design Document and follow coding standards and best practices. Your development teams use IDEs, compilers and version control systems like Git to manage code.
Key activities include coding, code reviews, unit testing and static code analysis. Regular code reviews help identify potential issues early and verify adherence to standards. Your team breaks down the project into smaller, manageable coding tasks that can be completed daily.
The output of this phase is functional software that embodies the planning, analyzing and designing efforts from earlier stages.
Testing And Quality Assurance
Quality assurance plays a critical role in any software development lifecycle. The International Software Testing Qualifications Board defines quality assurance as activities focused on providing confidence that quality requirements will be fulfilled. Testing involves executing programs to identify defects and verify that software behaves as expected.
Practice shows that software errors detected late become expensive to fix, as the cost of an error increases throughout the software development process. Testing early and often through iterative approaches proves beneficial. Automated testing boosts efficiency and increases test coverage while providing immediate feedback on code changes. It’s also an important factor for development cost as well.
Deployment To Production
Your software moves to the production environment where end users can access it after rigorous testing. The deployment phase includes packaging, environment configuration and installation. Your team sets up production environments and conducts smoke testing on the live environment.
Deployment strategies vary based on project needs. Options include Big Bang, Blue-Green or Canary deployments. Your deployment process requires monitoring changes as they roll out live to users. Teams can initiate a rollback to remove changes and revert to the last known safe version when errors occur in production.
DevOps engineers and release managers handle deployment activities and minimize downtime while optimizing performance for a satisfying user experience.
Maintenance And Support
The software development life cycle doesn’t end at deployment. Maintenance begins right after deployment and continues throughout the software’s operational lifetime. Studies reveal that 75% of a system’s lifespan cost is occupied by maintenance. Some sources indicate maintenance can cost up to two-thirds of the software process cycle.
Maintenance covers corrective, preventative, perfective and adaptive activities. Corrective maintenance addresses faults and errors. Preventative maintenance looks into the future to keep software working as long as possible. Any software becomes obsolete over time without maintenance.
Typical Software Development Timeline Breakdown
Project complexity determines how long your software development timeline will extend. Breaking down timelines by application type provides realistic expectations for project planning and resource allocation.
Simple Applications Timeline
Simple applications require 2-4 months from start to finish. These projects have basic utility tools, single-purpose applications, or straightforward mobile apps with limited screens and minimal backend requirements.
Your requirements and design phase consumes 2-4 weeks. This original stage has understanding your idea, creating wireframes, and getting stakeholder approval. Development follows with backend API creation taking 5-10 weeks and frontend work requiring another 4 weeks. Integration testing and bug fixes occupy the final week before launch.
Simple apps typically feature user authentication, basic CRUD operations, and standard UI components. Building for both iOS and Android adds 40-60% to your development timeline. React Native or Flutter reduces this overhead to 20-30%.
Medium Complexity Projects Timeline
Medium complexity projects stretch your software development timeline to 4-8 months. These applications incorporate user accounts, payment processing, and third-party API integrations.
The analysis phase extends to 1-2 weeks for detailed documentation. UI/UX and architecture design require 2-3 weeks as your team maps user journeys and technical planning. Development spans 6-8 weeks with features built in stages. Testing and optimization take another 2-3 weeks. You should expect around 3 months for completion overall.
Custom design adds 3-4 weeks to your project timeline. Each major integration increases duration by 2-3 weeks. Payment processing requires an additional 2 weeks. Real-time features like messaging extend timelines by 3-4 weeks. These additions combine to affect your whole development process substantially.
Complex Enterprise Software Timeline
Complex enterprise applications just need 7-12+ months for successful completion. Banking apps require 9-12 months. Social networks stretch to 12-18 months. Marketplace platforms need 10-15 months. Healthcare platforms with HIPAA compliance extend to 12-18 months.
Your project qualifies as complex when it has 25+ screens, both administrative and user applications, or supports multiple platforms. Integration with multiple systems like CRM or ERP increases complexity. Data migration from older systems adds substantial time.
Discovery and feasibility studies consume 1-2 months. Architecture and system design require another 1-2 months for adaptable. Development proceeds in phases over 4-8 months. Testing, security audits, and compliance verification run continuously throughout the development phase. The whole project typically spans 9-12 months.
MVP Development Timeline
MVP development service offers a faster path to market. Standard web or mobile MVPs take 3-6 months. The average MVP requires 4.5 months according to industry surveys.
Simple MVPs with focused feature sets complete in 8-12 weeks. These have 5-15 screens, single user roles, and minimal integrations. Discovery takes 1 week, design requires 1 week, development spans 4-6 weeks, testing occupies 1 week, and launch needs 1 week.
Medium complexity MVPs with multiple user roles and payment processing extend to 12-20 weeks. Complex enterprise MVPs with AI capabilities or regulatory compliance stretch to 20-40 weeks.
No-code MVPs launch in 4-8 weeks. Complex fintech or healthcare MVPs require 6-9 months once you factor in compliance reviews and security integrations.
User accounts, payment processing, third-party API integrations
Complex Enterprise Software
9–12+ Months (Up To 18+)
25+ screens, admin + user panels, CRM/ERP integration, data migration
Simple MVP
8–12 Weeks
5–15 screens, single user role, minimal integrations
Medium MVP
12–20 Weeks
Multiple user roles, payment integration
Complex MVP
20–40 Weeks
AI features, regulatory requirements, enterprise integrations
No-Code MVP
4–8 Weeks
Basic workflows, validation-focused builds
Software Development Methodologies And Their Impact On Timelines
Choosing the right software development methodology shapes your development timeline more than any other factor. Each methodology brings distinct characteristics that accelerate or extend your project timeline based on how teams approach building software.
Agile And Scrum Methodology
Software developers realized traditional methods weren’t working, and Agile emerged. They started mixing old and new ideas until they found combinations that worked. These methodologies emphasized close collaboration between development teams and business stakeholders, frequent delivery of business value, and smart ways to craft, confirm and deliver code.
Scrum is one of the most popular agile methodologies. Jeff Sutherland and Ken Schwaber developed Scrum during the early 1990s to respond to challenges of managing complex software projects. The framework helps teams organize work through values, principles and practices. Scrum encourages teams to learn through experience, self-organize while working on problems, and reflect on successes and failures to improve.
Waterfall Approach
The waterfall model performs typical software development life cycle phases in sequential order. Each phase is completed before the next starts, and the result of each phase drives subsequent phases. Waterfall is among the least iterative and flexible methodologies, as progress flows in one direction through conception, requirements analysis, design, construction, testing, deployment and maintenance.
Waterfall methodologies result in a project schedule with 20-40% of the time invested for the first two phases, 30-40% of the time to coding, and the rest dedicated to testing and implementation. Time spent early can reduce costs at later stages. A problem found early is cheaper to fix than the same bug found later by a factor of 50 to 200.
DevOps And Continuous Integration
Continuous integration is a DevOps software development practice where developers merge code changes into a central repository on a regular basis, after which automated builds and tests are run. The key goals of continuous integration are to find and address bugs quicker, improve software quality and reduce the time it takes to confirm and release new software updates.
Developers commit to a shared repository using a version control system with continuous integration. A continuous integration service builds and runs unit testing on new code changes to surface any errors right away. This helps your team be more productive by freeing developers from manual tasks and encouraging behaviors that reduce errors and bugs released to customers.
Hybrid Methodologies
Many organizations adopt hybrid approaches, combining elements from various methodologies to create customized software development processes. Flexibility and adaptability remain key considerations. The development towards hybrid software development methods addresses challenges that arise when single methodologies don’t fit specific project needs.
Hybrid methodologies allow you to take the predictable planning of waterfall for certain phases while maintaining agile flexibility for others. Your project team can use waterfall for infrastructure setup and regulatory documentation while applying agile techniques for feature development. This combination provides structure where needed and speed where beneficial for your software development project.
Key Factors That Affect Your Development Timeline
A software development timeline rarely depends on one factor. Several variables shape how long your software development project takes. Clear awareness of these elements helps set realistic expectations, protect project scope, and support project success across the entire development process.
Team Size And Structure
Team size directly affects your development timeline. A study of 491 software projects found that teams with 3–7 members delivered the best outcomes. Groups of 5–9 developers reached peak productivity. Smaller teams reduce communication gaps and support faster decision making.
Large development teams often slow progress. More people increase coordination effort and project management overhead. Smaller agile teams move faster because fewer approval layers exist. Clear roles, skilled software developers, and strong collaboration help track progress and maintain software quality across every project phase.
Technology Stack Choice
Technology stack selection shapes the entire development process. Mature frameworks with strong ecosystems reduce time spent on basic setup. Teams that use familiar stacks work up to 40% faster compared to new or experimental tools.
A unified startup tech stack such as full JavaScript for frontend and backend reduces handoff delays. Strong documentation and community support speed up troubleshooting. Poor stack decisions increase technical debt and extend the development phase. The right technical architecture balances speed, scalability, and long-term maintainability for high quality software.
Third Party Integrations
Most software projects rely on third party integrations. Payment gateways, CRM systems, and analytics tools require API setup and testing. Each integration typically adds 1–2 weeks to your project timeline.
Research shows the average business uses over 300 SaaS applications. Without proper integration, data silos appear. Integration issues often surface late in the testing phase. That delay impacts the entire project. Careful planning, early API validation, and integration testing reduce timeline risks and protect software’s reliability.
Regulatory And Compliance Needs
Regulated industries face longer development timelines. Finance, healthcare, and fintech projects must follow GDPR, HIPAA, or PCI standards. Security testing and compliance reviews can extend timelines by 20–35%.
Compliance requires documentation, audits, and continuous monitoring. Smaller companies struggle without dedicated compliance teams. Additional security testing, performance testing, and system testing increase workload. Risk management becomes critical. Regulatory demands affect resource allocation and can delay successful completion if not addressed early in the analysis phase.
Project Scope And Complexity
Project complexity strongly influences your software development timeline. Applications with 25+ screens, multiple user roles, and complex business logic require longer development stages. Data migration from existing systems adds more time.
Scope changes during the development phase create delays. Each added feature affects the project plan and resource allocation. Clear project requirements and defined project goals reduce uncertainty. Strong project management protects the entire project from unnecessary timeline extensions.
Testing And Quality Standards
Rigorous testing protects software quality but extends timelines. Unit testing, integration testing, system testing, security testing, and user acceptance testing all require structured effort. Skipping them risks failure after launch.
Regular code reviews improve software’s reliability. Performance testing ensures software runs smoothly under load. Projects with strict quality benchmarks require more time in the testing process. However, this investment reduces bug fixes after release and supports long-term customer satisfaction.
Methodology And Workflow
Software development methodology influences pace and flexibility. Agile methodologies allow faster iterations and early user feedback. Agile techniques break work into manageable sprints and reduce risk.
Traditional models with rigid phases may slow adaptation. Rapid application development shortens cycles but requires experienced development teams. A structured development process with clear project planning and defined key phases improves alignment. Methodology choice affects the software’s lifecycle and determines how efficiently teams move from analysis phase to maintenance phase.
How To Move From Development To Staging Environment
Staging environments bridge the gap between development and production in your software development timeline. This intermediate phase provides a safe testing ground where you can verify changes without risking your live application.
Stage Environment Setup
A staging environment is a test sandbox isolated from production. Your staging setup should be a near-perfect replica of your production environment. This means matching production hardware, operating systems, network configurations and resource allocation.
Infrastructure parity will give accurate testing conditions. Staging should use the same setup if production runs on AWS with specific instance types. Your configuration settings in staging arrange with production settings. The only differences should be endpoints and necessary safety measures.
Data management requires careful planning. Most teams use production data snapshots or realistic test data. You need enough volume and variety to test ground scenarios without exposing sensitive information. Many teams use data masking or synthetic data generation to achieve this balance.
Pre-Production Testing
Pre-production testing catches issues before they affect users. Alpha testing environments are used after integration testing for performance and quality assurance. This involves performing end-to-end tests in a lab or stage environment to analyze performance under various fabricated conditions.
Beta testing environments occur after alpha tests complete. This involves releasing software to select users for further feedback before full release into production environments. The goal is to get ground feedback and identify any issues before public release.
Performance And Load Testing
Load testing in staging environments presents unique challenges. No test lab can mirror the production environment completely. The purchase of duplicate production hardware for testing is too expensive and the process of cloning production data too cumbersome.
Testing environments are often nowhere near as large as production counterparts. Testing on a couple of white box servers with the same operating system and database versions does not mean the application will perform under ground loads.
Production Deployment And Launch Process
Moving your software to production requires careful execution. Your deployment strategy determines how new code reaches users and how quickly you can recover from issues.
Deployment Strategies
Blue/green deployment uses two similar production environments running different versions of your application. You deploy to the inactive environment, test it really well, and switch traffic over. This provides quick rollback by switching back to the original environment. The method maintains two environments at once and ensures no downtime. Seamless rollbacks happen should an incident occur.
Canary deployments reduce risk by releasing new versions to small user subsets first. As you gain confidence, you deploy the changes bit by bit to replace the current version in its entirety. Rolling deployments adopt a gradual rollout approach where changes expose to increasing user percentages bit by bit until fully released. This strategy reduces big-bang deployment risks since issues affect only user subsets at any given time.
Production Monitoring Setup
Application Performance Monitoring gives you a view into your application stack before issues affect users. APM monitors critical components like application dependencies and server resources. Key metrics include response time, error rate, and throughput.
Performance baselines help you spot anomalies early. Test everything really well to determine acceptable response times and error rates. Standardizing application names avoids confusion across environments. Tags such as application name and environment help with organization.
Rollback Planning
Around 70% of downtime is caused by system changes. A rollback plan documents your strategy for reverting software back to a previously known stable state when something goes wrong. Define trigger conditions including error log spikes, crash reports, or key metric drops.
Your rollback plan must include detailed step-by-step instructions for reverting changes. Assign specific names rather than teams for clarity during incidents. Establish clear rollback timeboxes for triggering decisions. Plan internal and external communications to alert stakeholders.
Common Timeline Challenges And How To Overcome Them
Development is rarely linear. Software projects encounter obstacles that extend your software development timeline beyond original estimates. Your development teams can maintain project success if they understand these challenges.
Scope Creep Management
Scope creep affects 52% of projects. This happens when features slip in without formal review and budgets balloon while timelines slide. Unclear project scope makes it simple for new features to enter unnoticed. Inadequate project planning and changing stakeholder requirements compound the problem.
You need written agreements detailing project requirements and deliverables. Designate a Product Owner to manage scope changes. Direct all changes through this owner who assesses the effect on your project timeline. Maintain regular communication with stakeholders about what scope changes mean.
Resource Constraints
Resource constraints affect 48% of projects by a lot. Limited skilled personnel, tight budgets and time limits create substantial hurdles. Insufficient resources lead to missed deadlines and project delays.
Conduct a full resource analysis during project planning. Promote T-shaped development teams with broad specialization. Use project management software to track utilization and identify bottlenecks.
Technical Debt
Technical shortcuts accumulate as messy codebases that slow future development. Teams rush delivery and create technical debt through poor code quality. This forces reactive firefighting instead of building new value.
Allocate time to refactor in each sprint. Track technical debt areas and plan resolution during less intense periods. Focus on regular code reviews to maintain cleaner codebases.
Communication Gaps
Poor communication costs companies $62.40 million on average each year. 86% of employees blame project failures on inadequate teamwork and poor communication. Misunderstandings between developers and stakeholders lead to rework and delays.
Establish clear communication channels from the start. Hold regular meetings to keep everyone arranged. Implement the Three Amigos approach with developer, tester and business analyst working together to clarify requirements.
How GainHQ Supports Your Software Development Timeline
GainHQ helps businesses plan and execute a realistic software development timeline from the start. The team begins with clear project planning, defined project requirements, and a structured project scope. That early clarity protects the entire development process and reduces scope changes later. Each software development project follows defined key phases so the development timeline stays aligned with business goals and realistic expectations.
An experienced project manager and skilled development teams track progress across every project phase. Strong resource allocation and risk management keep the software development process stable. Unit testing, integration testing, system testing, and user acceptance testing ensure high-quality software before release.
Agile methodologies, regular code reviews, and detailed documentation strengthen software quality and software reliability. GainHQ ensures software aligns with strategy while supporting long-term project success.
FAQs
Can a software development timeline change after the project starts?
Yes, a software development timeline can shift if project scope changes or new project requirements appear. Scope creep, third-party integrations, or regulatory updates often extend the development process. Strong project management and risk management reduce unexpected delays.
Is it possible to shorten a software development timeline without affecting software quality?
Yes, but only with careful resource allocation and the right software development methodology. Agile methodologies, rapid application development, and automated software testing can improve efficiency. Cutting core testing phase activities, however, will hurt software quality and software’s reliability.
Does remote collaboration affect the software development timeline?
Yes, remote development teams can impact the development timeline if communication gaps exist. Clear documentation, regular code reviews, and structured workflows keep the entire development process aligned. Modern tools help track progress across each project phase.
Can early user feedback reduce delays in a software development project?
Yes, early user feedback during development stages helps validate project goals and avoid costly rework. Feedback improves user interfaces and ensures software aligns with customer expectations. This reduces major revisions late in the testing phase.
How do budget constraints influence a typical software development timeline?
Budget limits directly affect team size, technology stack choice, and testing depth. Limited resources may extend the development phase or reduce feature scope. Clear project planning helps balance realistic expectations with successful project outcomes.
Modern cloud-native systems rely heavily on the application programming interface as the foundation for scalable architecture. Teams once depended on a code first approach, where developers wrote backend logic before defining how services communicate. That model created gaps in web development, delayed early feedback, and made it harder to build apis that aligned with business goals.
An api first company instead prioritizes designing contracts before developing apis, which clarifies why api strategy matters across the entire system. Clear specifications help teams manage internal apis, handle sensitive data, and ensure secure ways to transfer data between services.
Standard formats like query language structures also improve consistency. With this method, teams can automate processes, conduct load testing earlier, and define functionality in a single line contract that guides development beyond traditional code first limitations.
What Is API-First Architecture In Cloud-Native Development
API first architecture in cloud-native development means treating your api design as the primary deliverable before writing implementation code. Teams create an api specification using formats like OpenAPI 3.1 or GraphQL SDL, defining api endpoints, data models, and http methods upfront. This api contract becomes the single source of truth for frontend developers, backend engineers, and third party developers alike.
Industry data shows that applications must reach market in six months or less to stay competitive. The api first methodology supports this timeline by enabling parallel development workflows. Frontend teams build against mock servers while backend engineers implement the core functionality. By 2026, analysts predict that 80% of enterprises will adopt some form of api first strategy for their software development process. Cloud-native systems depend on this approach because microservices require stable, well defined apis to communicate reliably across distributed environments.
7 Benefits Of API-First Architecture
API-first architecture plays a critical role in cloud-native development by enabling scalable, modular, and integration-ready systems. Clear API contracts allow teams to build, deploy, and evolve services faster without dependency bottlenecks.
1. Faster Microservices Deployment
Microservices architecture breaks large applications into smaller, independent services that communicate through apis. When you adopt an api first design, each service gets a clear api contract before development begins. This clarity eliminates the back-and-forth confusion that typically slows down development teams working on interconnected services.
The development process becomes predictable. Engineers know exactly what api requests each service accepts and what http status code responses to expect. Swiss Federal Railways adopted mandatory api first reviews and reported significant improvements in api quality and discoverability across their entire api lifecycle. Their standardized approach reduced deployment friction because services could integrate without extensive coordination meetings.
2. Stronger System Decoupling
Decoupling means that changes in one service do not break others. API first architecture enforces this separation by treating the api as a boundary between components. Each service owns its internal logic, but the api adheres to a published contract that consumers depend on.
Consider a scenario where your billing service needs a complete rewrite. With proper api design, you can replace the entire system behind the api without touching any consuming applications. The api endpoints remain stable. The data model stays consistent. Frontend applications, mobile apps, and third party services continue working normally.
This decoupling supports team autonomy. Different development team groups can own different services without constant coordination. One team manages user authentication. Another handles inventory. A third focuses on order processing. Each team operates independently as long as their apis follow the agreed specification.
3. Scalable Service Communication
Cloud-native applications handle variable traffic loads. API first architecture makes scaling straightforward because services communicate through standardized interfaces. When one service experiences high demand, you scale that specific service without affecting others.
Rest apis with proper http methods handle this gracefully. Load balancers distribute api traffic across multiple instances of a service. The api contract remains unchanged regardless of how many instances exist behind it. Consumers send api requests to the same endpoints whether one server or fifty servers process them.
4. Seamless Multi-Cloud Integration
Modern businesses rarely run on a single cloud provider. API first architecture simplifies multi-cloud deployments because apis abstract away infrastructure differences. A service running on AWS communicates with another service on Azure through standardized api calls.
The api acts as the integration layer. It does not matter which programming language each service uses or which cloud platform hosts it. The api specification defines the contract. Any service that implements that contract can participate in the system.
5. Improved Developer Productivity
Developer experience directly impacts how much effort teams spend building and maintaining software. API first architecture improves this experience through clear documentation, consistent patterns, and automation-friendly interfaces.
Interactive documentation generated from OpenAPI specifications lets developers save time learning new apis. Tools like Swagger create browsable api documentation automatically. Developers explore api endpoints, see request and response examples, and even test api calls directly from the documentation. This reduces onboarding time for new features and new team members.
Thorough documentation also helps non technical team members understand what the system can do. Product managers reference the api documentation when planning features. Support staff check api documentation to troubleshoot customer issues. Api stakeholders across the organization benefit from clear, accessible specifications.
6. Consistent Governance And Security
Api governance ensures that all apis in your organization follow consistent standards. API first architecture makes governance practical because every api starts with a reviewable specification document.
Before any code gets written, other stakeholders review the api design. They check naming conventions, response formats, authentication requirements, and versioning strategies. Problems caught at this stage cost far less to fix than issues discovered after implementation.
Api security improves when security requirements appear in the specification from day one. OAuth 2.0 flows, api keys management, and json web tokens authentication all get defined during api design. The implementation must protect data according to the documented security model.
7. Future-Proof Architecture Flexibility
Technology changes rapidly. API first architecture protects your investment by decoupling your interfaces from their implementations. When new features, new languages, or new platforms emerge, your apis remain stable while internals evolve.
Building blocks of your system can be replaced independently. A service written in Java today might become a Rust service tomorrow if performance demands it. The api contract does not change. Consumers never know the difference.
Versioning strategies handle breaking changes gracefully. When you must change an api in ways that affect consumers, you release a new version at a different path. Old consumers continue using the previous version until they migrate. This prevents the chaos of forcing all consumers to update simultaneously.
Why Cloud-Native Systems Depend On API-First Design
Cloud-native architecture assumes that services run as independent units that communicate over networks. This distributed nature requires reliable, well documented interfaces between every component. API first design provides exactly this reliability.
Service Discovery And Communication
Services in cloud-native environments come and go dynamically. Containers start and stop based on demand. API first design means each service advertises a stable interface regardless of where it runs. Service discovery mechanisms route api traffic to healthy instances automatically.
Container Orchestration Integration
Kubernetes and similar platforms manage thousands of containers across clusters. These orchestrators need to understand how services communicate. Well defined apis with health check endpoints let orchestrators route traffic intelligently. Failing services get removed from load balancers before they degrade user experience.
Event-Driven Architecture Support
Cloud-native systems often combine synchronous api calls with asynchronous events. API first thinking applies to both patterns. Event schemas define the data model for messages just as api specifications define request and response formats. Consumers depend on stable contracts whether they receive data through api requests or event streams.
Observability And Monitoring
Distributed systems need extensive monitoring. API first architecture makes observability practical because every interaction follows documented patterns. Monitoring tools track api requests, response times, and error codes consistently. When problems occur, engineers trace api calls across services to identify root causes.
Continuous Deployment Pipelines
Cloud-native teams deploy frequently, sometimes multiple times per day. Api testing validates compatibility before each deployment. Automated testing suites verify that api endpoints return expected responses. Contract tests confirm that producers and consumers remain aligned. This testing confidence enables the rapid deployment cadence that cloud-native development demands.
Key Components Of An API-First Cloud-Native Stack
Building an api first cloud-native system requires specific tools and practices. Each component serves a purpose in the software development lifecycle from design through production operation.
API Specification Formats
OpenAPI Specification in YAML or JSON format describes rest apis comprehensively. The specification covers endpoints, parameters, request bodies, responses, and authentication. GraphQL SDL serves a similar purpose for GraphQL apis. These machine-readable formats enable automation throughout the entire api lifecycle.
Mock Server Infrastructure
Mock servers like WireMock simulate api behavior before real implementations exist. Frontend teams build complete user interfaces against mocked responses. Quality assurance tests edge cases without depending on fragile test environments. Mock apis accelerate the development process significantly.
Contract Testing Tools
Pact and similar tools verify that api producers and consumers agree on contracts. Consumer tests define expectations. Producer tests confirm implementations meet those expectations. Mismatches fail builds before reaching production, preventing integration failures that frustrate users.
API Gateway Management
Gateways handle cross-cutting concerns like authentication, rate limiting, and routing. They sit between consumers and your services, enforcing api governance policies consistently. Modern gateways support both rest apis and GraphQL, routing api traffic appropriately based on request characteristics.
Documentation Generation
Tools generate interactive documentation from api specifications automatically. Swagger UI creates browsable interfaces where developers explore endpoints and test api calls. This api documentation stays synchronized with the actual implementation because both derive from the same specification source.
Common Challenges In API-First Cloud-Native Adoption
Transitioning to api first development involves organizational and technical changes. Understanding common challenges helps teams prepare and succeed.
Initial Design Overhead
Api first requires upfront investment in design before visible progress appears. Teams accustomed to shipping user interface prototypes quickly may feel frustrated. The api design process takes time, involving workshops with api stakeholders, domain modeling, and specification writing. This investment pays dividends later but requires patience initially.
Team Skill Gaps
Not every developer has experience designing apis as products. Skills like resource modeling, versioning strategy, and security design need development. Some teams benefit from training or consulting during initial adoption. Internal developers may need guidance on http methods, error handling patterns, and api security best practices.
Legacy System Integration
Existing systems often lack clean api boundaries. Databases expose internal schemas directly. Monolithic applications tangle business logic with data access. Creating facade apis in front of legacy systems takes effort. Teams must balance modernization against ongoing feature delivery.
Governance Process Resistance
Lightweight governance improves quality, but excessive process slows teams down. Finding the right balance requires iteration. Some organizations over-engineer review processes that frustrate developers. Others skip reviews entirely and end up with inconsistent apis. Effective api governance involves just enough oversight to maintain standards without becoming bureaucratic.
Cultural Shift Requirements
API first changes how teams think about their work. Engineers become interface designers. Product managers must understand api consumers. Success requires buy-in across the organization. Teams that treat api first as purely a technical initiative often struggle compared to those who embrace the organizational changes involved.
How GainHQ Supports API-Driven Cloud-Native Teams
GainHQ understands that modern development teams need tools designed for integration from the start. The platform applies api first architecture principles to help businesses build scalable, maintainable systems without the integration headaches that slow traditional development.
GainHQ accelerates api development through integrated api management tools. Teams design, mock, test, and deploy apis rapidly using workflows optimized for microservices architecture. The platform supports parallel development for web and mobile teams, ensuring consistent api contracts across all consumers.
Analytics capabilities track api traffic and usage patterns, helping teams optimize performance and maintain api security. Companies using GainHQ report faster time-to-market and greater reusability of services. For teams adopting api first strategy, GainHQ provides the building blocks needed to succeed. Learn more at gainhq.com.
FAQs
How Does API-First Architecture Improve Cloud Scalability?
API first architecture improves scalability by creating clear boundaries between services. Each service scales independently based on its specific load requirements. When one api endpoint receives heavy traffic, you add more instances of that service without scaling the entire system. Load balancers distribute api requests across instances automatically. This granular scaling approach uses cloud resources efficiently and keeps costs manageable.
What Is The Difference Between API-First And Service-Oriented Architecture?
Service-oriented architecture (SOA) focuses on organizing applications into reusable services. API first architecture focuses specifically on designing the interface before implementing the service. You can practice api first within SOA or microservices architectures. The key distinction is timing and priority. Api first means the api specification comes before code, while SOA describes how services relate to each other organizationally.
When Should Companies Transition To API-First Design?
Companies benefit from api first adoption when they face integration challenges, plan microservices migrations, or need to support multiple client applications from shared backends. Startups can adopt api first from their first sprint, avoiding costly rewrites later. Established companies often transition one domain at a time, creating facade apis for legacy systems while building new features api first.
How Does API-First Support Continuous Delivery Pipelines?
Api specifications enable automated testing throughout delivery pipelines. Contract tests verify that api changes remain compatible with consumers. Mock servers let teams test integrations without depending on shared environments. Code generation creates consistent client libraries automatically. These automations give teams confidence to deploy frequently, sometimes multiple times daily.
Which Tools Help Manage API Lifecycle Effectively?
Popular tools include OpenAPI for specification writing, Swagger for documentation generation, and Postman for api testing. WireMock creates mock servers for development. Pact handles contract testing between producers and consumers. API gateways like Kong or AWS API Gateway manage production traffic. Version control systems store api specifications alongside code, enabling proper change tracking and collaboration.
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager
1 minute
_gac_
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
PostHog is used to collect anonymous usage statistics and product interaction data to help improve website performance and user experience.
Used by PostHog to store anonymous analytics and track user interactions.
1 year
Functional cookies enable additional features such as live chat and personalized interactions. Some features may not work properly if these cookies are disabled.
Enables live chat functionality and session continuity.
Name
Description
Duration
chat_session_id
Maintains the user’s chat session during interactions with live chat.